Streams e Pipes
Dalton SereyO que são streams?
O termo stream é usado em diversos contextos na computação para se referir a qualquer fluxo de dados liberados sequencialmente ao longo do tempo. Perceba que diversas atividades, dispositivos e processos produzem dados dessa forma e podem ser vistos como fontes de streams. Também há também dispositivos e processos capazes de receber e ler dados externos dessa forma e podem, portanto, ser considerados consumidores de streams.
Essa abstração não é mero exercício acadêmico. Em geral, sua adoção tem o propósito de criar interfaces uniformes que permitam conectar e combinar, com mais facilidade, diferentes tipos de componentes.
Processos e Streams
No contexto específico de programação e de sistemas operacionais modernos, processos e a maioria dos dispositivos de entrada e saída são vistos como produtores e consumidores de streams de dados. Isso permite que seja oferecida uma interface de programação uniforme para a comunicação de um processo com tais dispositivos e com outros processos.
Em sistemas Unix e semelhantes (isto equivale à quase totalidade dos sistemas em uso hoje) todo processo, ao ser criado, tem automaticamente três streams abertos e disponíveis para uso imediato. São os chamados de standard streams: STDIN, STDOUT e STDERR. Assim, por definição e construção, todo processo Unix é, ao mesmo tempo, produtor e consumidor de streams.
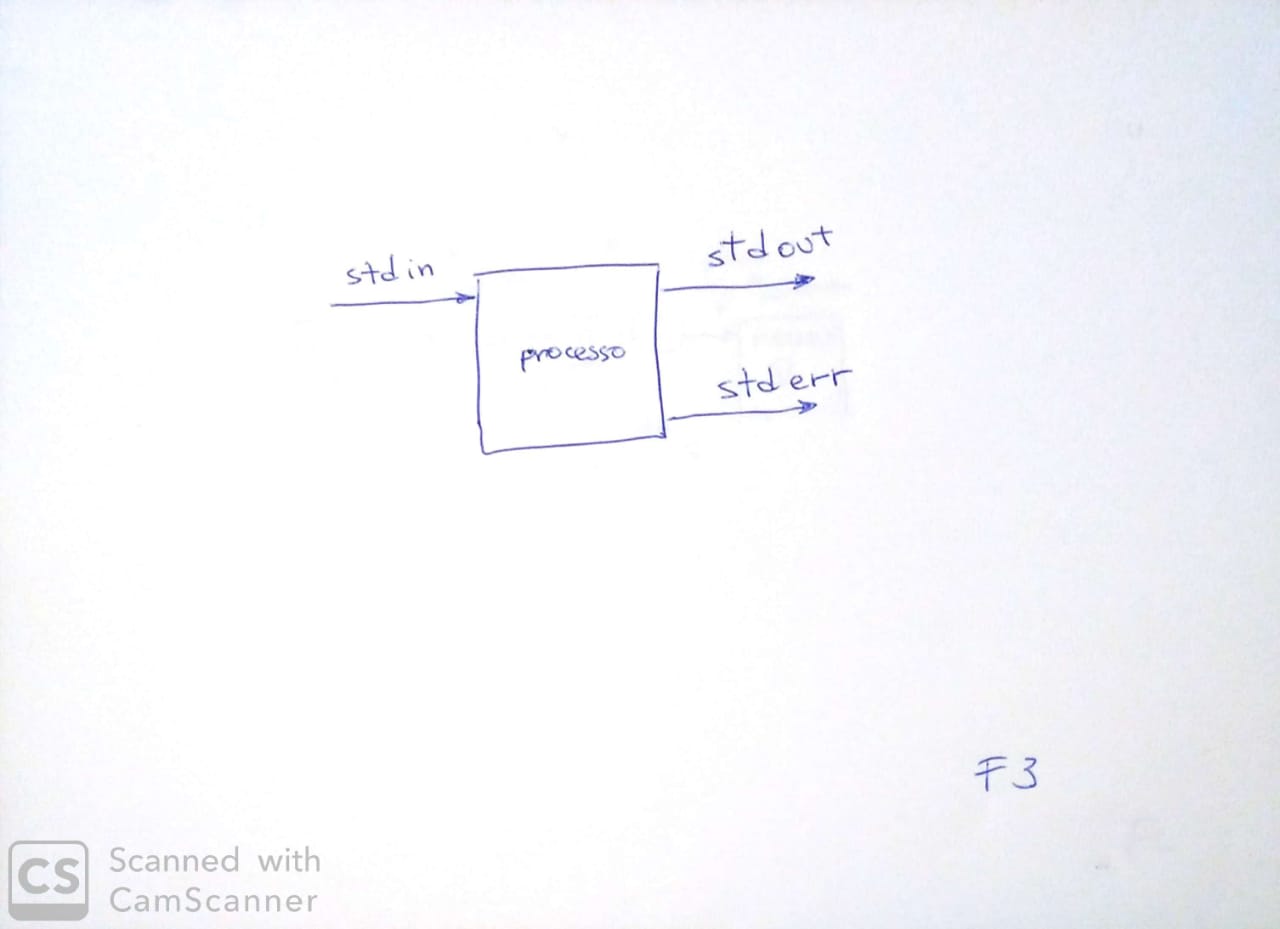
STDIN, ou entrada padrão, é o stream de entrada de dados e é a forma preferencial pela qual um processo deve obter dados externos durante seu funcionamento. STDOUT, ou saída padrão, é o stream de saída de dados e deve ser usado para externar os resultados do processo. Finalmente, há STDERR, também chamado de saída padrão de erro, que deve ser usado para imprimir mensagens de erro, bem como informes e registros de andamento do processo. A disponibilidade desses streams estimula a adoção do modelo de programação conhecido por entrada-processamento-saída ou, mais simplesmente, entrada-saída.
Um pouco mais adiante veremos o motivo pelo qual STDERR existe e por que usar STDIN para externar dados de erros e informes de andamento é, de modo geral, má ideia.
Ao executar um programa no shell, o usuário espera poder usar o teclado e a tela do terminal para interagir com o processo. Por esse motivo, sempre que um processo é iniciado em um shell, o sistema operacional conecta os streams do processo ao respectivo terminal. Mais especificamente, STDIN é conectado ao teclado e tanto STDOUT quanto STDERR são conectados à tela.
Um pouco de história: shell vs terminal
Muitos se confundem com os conceitos de shell e terminal hoje em dia. O problema é que, atualmente, ambos são executados como aplicativos e executam em janelas no ambiente gráfico. No passado, contudo, um terminal era o dispositivo físico que combinava, tipicamente, teclado e tela. Serviam exclusivamente como dispositivos de entrada e saída e não faziam qualquer forma de processamento. Sua função consistia apenas em enviar para o computador os caracteres digitados pelo usuário no teclado e exibir na tela os caracteres recebidos do computador – isso inclui, claro, códigos de controle, como os famosos LINE-FEED (
\n), CARRIAGE-RETURN (\r), TAB (\t), etc. Por ser um mercado interessante, diversos terminais com melhores características foram desenvolvidos. Um deles, o VT100 da DEC, foi um dos primeiros a ser capaz de reconhecer seqüências especiais de caracteres como forma de expandir as possibilidades de controle do terminal.Observe que isso se dava em um tempo em que um único computador (que era basicamente um processador) precisava ser compartilhado por um grande número de usuários. Por isso, era comum que os terminais fossem instalados distante do computador. Aliás, daí vem o nome: eram apenas terminais do computador, não o computador em si.
Hoje, a maioria dos computadores está integrado a seu próprio “terminal” físico (teclado e tela) e palavra perdeu um pouco o sentido original. A palavra, contudo, se manteve em nosso vocabulário e, hoje, designa qualquer aplicativo que simule (ou emule) um terminal de texto como os de antigamente. Observe, que esse tipo de app se concentra em oferecer uma boa experiência de uso, focando em questões visuais, como cores, fontes, etc. Curiosidade: a maioria dos aplicativos de terminais ainda hoje permitem modos de emulação do VT100.
E qual o papel do shell? O shell é o interpretador dos comandos emitidos pelo usuário. Seu papel não é lidar com tela e teclado, mas interpretar e despachar comandos. Observe que para usar um shell, você ainda precisa de um terminal.
Composição por Streams e Pipelines
Agora que sabemos que um processo pode ser visto como um consumidor e produtor de dados via streams, podemos nos perguntar: como tiramos proveito disso?
A percepção acima nos permite compreender processos e dispositivos como componentes. Pense neles como peças Lego que podemos conectar umas às outras para formar sistemas e obter os comportamentos desejados, sem que seja necessário recodificar, recompilar ou mesmo linkar os programas originais. Como a composição se dá em nível de processos e não de código, a ligação se dá pela conexão dos streams de saída de uns aos streams de entrada dos outros. Esse forma de composição é conhecida por pipeline (duto, encanamento) e é muito utilizada em sistemas Unix e semelhantes. De fato, serviu de inspiração e referência arquitetural para um enorme número de sistemas e linguagens, além de Unix.
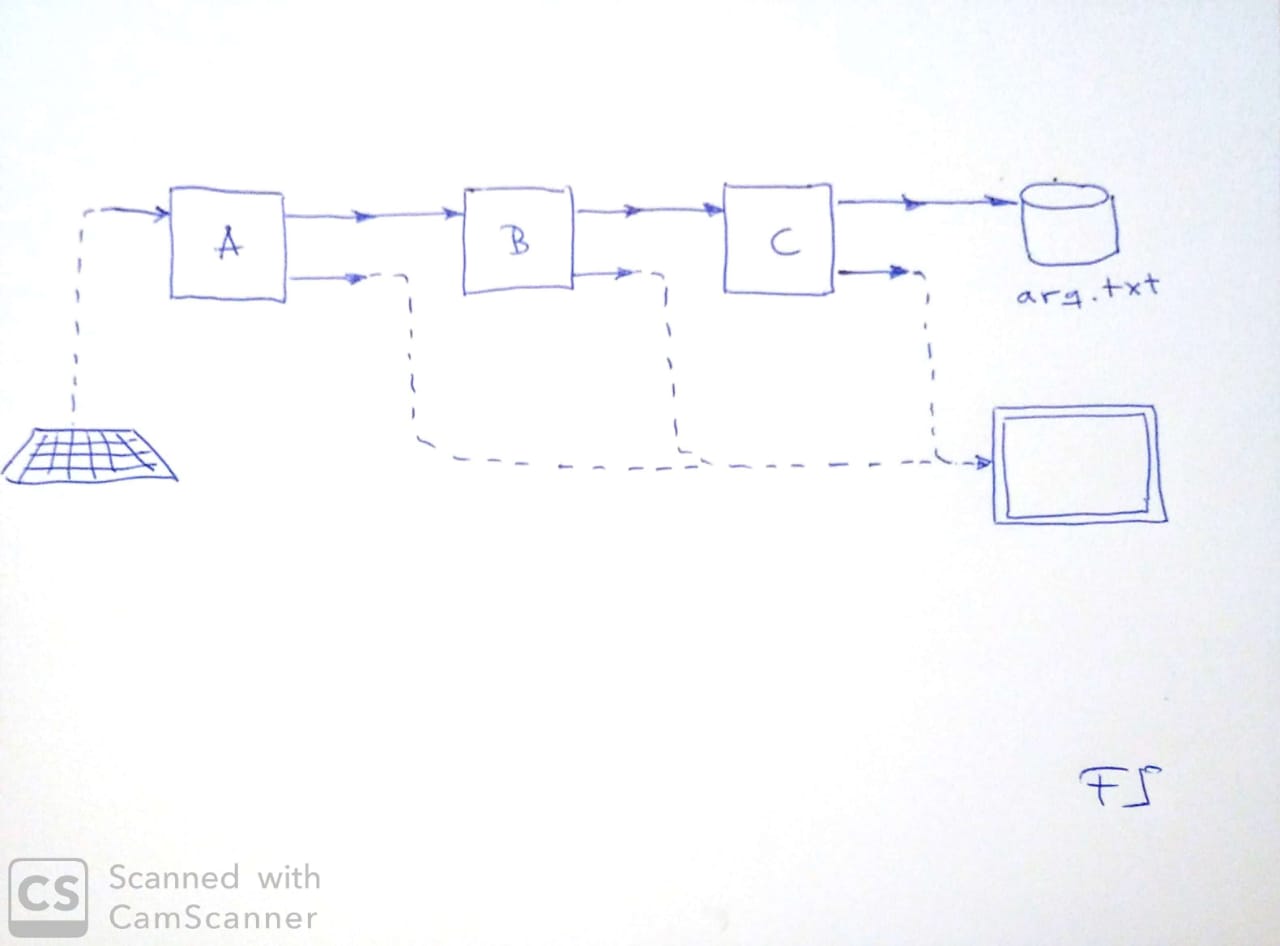
Na figura, vemos um exemplo simples de pipeline envolvendo o
terminal (teclado e tela), três processos e um arquivo. O sistema
ou processo resultante (ou meta-processo, se preferir), lê sua
entrada do teclado e armazena sua saída no arquivo arq.txt.
Além disso, usa a tela do terminal para exibir quaisquer
mensagens de andamento ou de erro que forem produzidas nas etapas
em que consiste.
É importante destacar que os processos em um pipeline são executados em paralelo (no mínimo, usando multi-programação). Isso é possível porque um processo pode, se for necessário, pausar sua operação, sempre que não tiver dados para processar em seu stream de entrada. De fato, esse é o comportamento default de qualquer processo.
Para conectar o stream de saída de um processo ao stream de entrada de um dispositivo ou de um segundo processo, o sistema operacional usa um conceito conhecido por pipe. Para conectar um processo a um arquivo, por sua vez, o SO usa um mecanismo um pouco diferente, mas relacionado, chamado de redirecionamento.
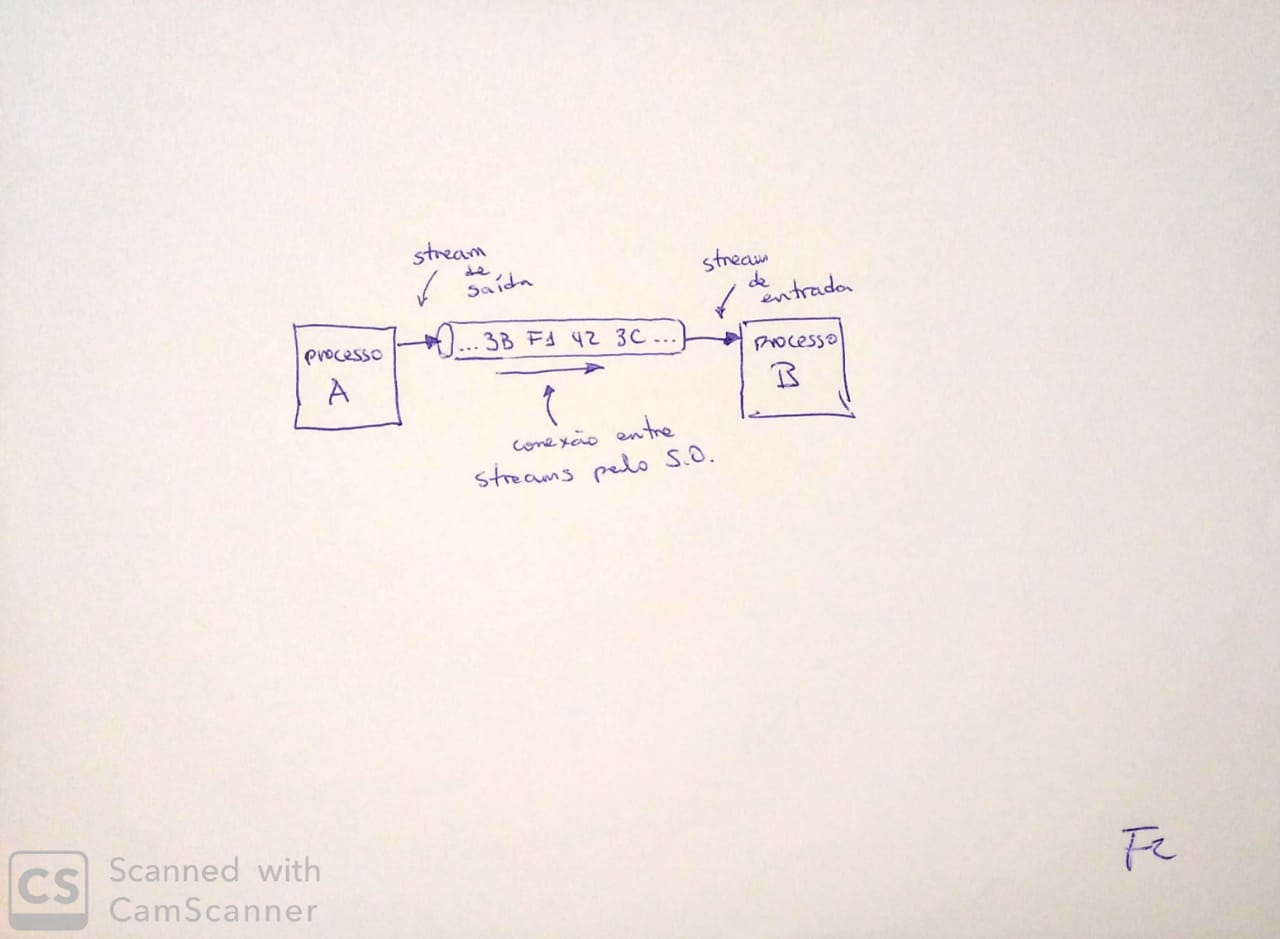
A figura abaixo ilustra a conexão de dois processos através de um pipe. A figura evidencia que o pipe é um componente adicional criado pelo SO, para conectar os streams. É importante destacarmos uma propriedade dos pipes: eles são bufferizados. Ou seja, eles armazenam os dados recebidos até que sejam lidos/consumidos. Essa característica é ilustrada na figura pelos bytes dentro do “tubo”. Embora tenham sido escritos no pipe pelo processo A, os dados ainda não foram lidos pelo processo B. Apesar disso, o pipe os manterá guardados até que sejam lidos. Quando forem lidos, contudo, os dados são imediatamente apagados do pipe e não podem ser lidos novamente. Observe que isso faz o pipe operar, essencialmente, como uma fila de comunicação entre os processos.
Como usar STDIN, STDOUT e STDERR
Talvez você esteja se perguntando: como posso escrever programas que usem STDIN, STDOU e STDERR? Provavelmente, você já faz isso.
Na maioria das vezes que aprendemos uma linguagem de programação,
precisamos começar com comandos simples de entrada e saída.
Tipicamente, esses comandos lidam com STDIN e STDOUT. Por
exemplo, as funções input() e print() de Python 3 lêem e
escrevem em STDIN e STDOUT, respectivamente. O mesmo ocorre com
System.out.println() e System.in.read(), de Java.
O uso de STDERR, contudo, pode requerer uma breve pesquisa na
Internet sobre a sintaxe que sua linguagem pede. Na maioria das
vezes, você usará a mesma função ou comando usado para STDOUT, ao
qual você adicionará algum parâmetro ou detalhe de sintaxe para
indicar que quer que a mensagem seja impressa em STDOUT. No caso
de Python 3, por exemplo, você precisa importar o módulo sys e,
com isso, terá acesso ao stream STDERR via sys.stderr. Assim,
para imprimir na saída de erro, basta usar print(mensagem,
file=sys.stderr).
Redirecionamentos e Pipes
Entendido o conceito de pipeline, podemos passar à sintaxe necessária para criá-los a partir do shell.
Observaçao. De fato, é o sistema operacional que cria e proporciona pipes e redirecionamentos. Na prática, contudo, é muito mais comum que o usuário final crie seus pipelines a partir do shell ou de outras linguagens de alto nível. Assim, a sintaxe específica para criar pipelines varia de uma linguagem para outra. Aqui, veremos apenas a sintaxe de Bash. Felizmente, essa sintaxe é simples, muito popular e se baseia na sintaxe no que é, provavelmente, o shell original de Unix (o Thompson Shell).
Abaixo apenas listarei os operadores e a sintaxe básica que usamos como cada operador. Lembre-se que a sintaxe abaixo pode ser usada para compor seus próprios programas. Para isso, basta que leiam e escrevam nos streams padrão. Também colocarei um exemplo simples. Aos interessados no assunto, informo que há muito mais o que se aprender sobre comunicação inter-processos, tanto no nível conceitual, quanto do ponto de vista prático.
Escrevendo STDOUT para um novo arquivo Para redirecionar a
saída padrão de um processo para um novo arquivo use o operador
>. Sintaxe: processo > nome-arquivo.
$ ls > arquivos.txt
Escrendo STDOUT para um arquivo existente Para redirecionar a
saída padrão de um processo para adicionar dados a um arquivo
existente, use o operador >>. Sintaxe: processo >>
nome-arquivo.
$ ls >> arquivos.txt
Lendo STDIN de um arquivo existente Para redirecionar a
entrada padrão de um processo de forma que leia dados de um
arquivo existente, use o operador <. Sintaxe: processo <
nome-arquivo.
$ wc < /etc/passwd
Você pode combinar redirecionamentos de STDIN e STDOUT em um único comando.
$ wc < /etc/passwd >> arquivo.txt
STDOUT de um processo para STDIN de outro Para conectar dois
processos, usamos o operador |. A sintaxe não poderia ser mais
simples: processo1 | processo2.
$ cat /etc/passwd | wc
A título de curiosidade. Compare o comando que usamos antes,
wc < /etc/passwd, com este último,cat /etc/passwd | wc. O primeiro usa um único processo e um redirecionamento. E o segundo usa dois processos conectados por um pipe. Ambos, contudo, produzem exatamente o mesmo resultado final.
A Filosofia Unix
Os conceitos discutidos acima são a base para o que se costuma chamar de filosofia Unix. Trata-se de um conjunto de normas culturais sobre como escrever programas que permitam maximizar as chances de combinar e, portanto, reusar o código produzido. Os preceitos da filosofia são simples e podem ser resumidos, ainda que de forma simplificada, a:
-
Cada programa deve fazer uma única coisa e deve fazê-la muito bem.
-
Programas devem ser criados prioritariamente para interagir com outros programas, via streams de texto.
Ainda poderíamos citar o preceito que diz que tudo é um arquivo. Este preceito é mais voltado para o design do SO, mas pode ser relevante para os desenvolvedores e usuário Unix. A ideia é que todo dispositivo ou conceito seja enquadrado sob a abstração de arquivo. E, de fato, quase tudo em um Unix é um arquivo: diretórios, dispositivos de entrada e saída, etc. Como consequência, todos eles podem ter uma representação (identificador) em algum lugar do sistema de arquivos e diretórios e devem poder aceitar comunicação baseada em streams, facilitando sua interoperação com os demais componentes e processos do sistema.
Essa cultura levou ao enorme e excelente conjunto de ferramentas de linha de comando de Unix (hoje disponíveis em Linux, em Mac e até no Windows). Todas essas ferramentas foram criadas sob essa filosofia. Como consequência, todas elas podem ser compostas umas com as outras, permitindo que o usuário obtenha comportamentos novos a cada comando, sem que haja a necessidade de reescrever ou recompilar qualquer código. É disso que surge o conhecido poder da linha de comando Unix.